 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Based Hdr Reconstruction
Papers and Code
GMODiff: One-Step Gain Map Refinement with Diffusion Priors for HDR Reconstruction
Dec 18, 2025

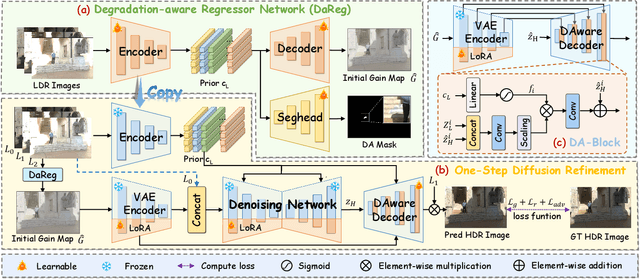

Pre-trained Latent Diffusion Models (LDMs) have recently shown strong perceptual priors for low-level vision tasks, making them a promising direction for multi-exposure High Dynamic Range (HDR) reconstruction. However, directly applying LDMs to HDR remains challenging due to: (1) limited dynamic-range representation caused by 8-bit latent compression, (2) high inference cost from multi-step denoising, and (3) content hallucination inherent to generative nature. To address these challenges, we introduce GMODiff, a gain map-driven one-step diffusion framework for multi-exposure HDR reconstruction. Instead of reconstructing full HDR content, we reformulate HDR reconstruction as a conditionally guided Gain Map (GM) estimation task, where the GM encodes the extended dynamic range while retaining the same bit depth as LDR images. We initialize the denoising process from an informative regression-based estimate rather than pure noise, enabling the model to generate high-quality GMs in a single denoising step. Furthermore, recognizing that regression-based models excel in content fidelity while LDMs favor perceptual quality, we leverage regression priors to guide both the denoising process and latent decoding of the LDM, suppressing hallucinations while preserving structural accuracy. Extensive experiments demonstrate that our GMODiff performs favorably against several state-of-the-art methods and is 100 faster than previous LDM-based methods.
Learning Continuous Exposure Value Representations for Single-Image HDR Reconstruction
Sep 07, 2023Deep learning is commonly used to reconstruct HDR images from LDR images. LDR stack-based methods are used for single-image HDR reconstruction, generating an HDR image from a deep learning-generated LDR stack. However, current methods generate the stack with predetermined exposure values (EVs), which may limit the quality of HDR reconstruction. To address this, we propose the continuous exposure value representation (CEVR), which uses an implicit function to generate LDR images with arbitrary EVs, including those unseen during training. Our approach generates a continuous stack with more images containing diverse EVs, significantly improving HDR reconstruction. We use a cycle training strategy to supervise the model in generating continuous EV LDR images without corresponding ground truths. Our CEVR model outperforms existing methods, as demonstrated by experimental results.
HistoHDR-Net: Histogram Equalization for Single LDR to HDR Image Translation
Feb 08, 2024



High Dynamic Range (HDR) imaging aims to replicate the high visual quality and clarity of real-world scenes. Due to the high costs associated with HDR imaging, the literature offers various data-driven methods for HDR image reconstruction from Low Dynamic Range (LDR) counterparts. A common limitation of these approaches is missing details in regions of the reconstructed HDR images, which are over- or under-exposed in the input LDR images. To this end, we propose a simple and effective method, HistoHDR-Net, to recover the fine details (e.g., color, contrast, saturation, and brightness) of HDR images via a fusion-based approach utilizing histogram-equalized LDR images along with self-attention guidance. Our experiments demonstrate the efficacy of the proposed approach over the state-of-art methods.
ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation
Sep 07, 2023



High Dynamic Range (HDR) content creation has become an important topic for modern media and entertainment sectors, gaming and Augmented/Virtual Reality industries. Many methods have been proposed to recreate the HDR counterparts of input Low Dynamic Range (LDR) images/videos given a single exposure or multi-exposure LDRs. The state-of-the-art methods focus primarily on the preservation of the reconstruction's structural similarity and the pixel-wise accuracy. However, these conventional approaches do not emphasize preserving the artistic intent of the images in terms of human visual perception, which is an essential element in media, entertainment and gaming. In this paper, we attempt to study and fill this gap. We propose an architecture called ArtHDR-Net based on a Convolutional Neural Network that uses multi-exposed LDR features as input. Experimental results show that ArtHDR-Net can achieve state-of-the-art performance in terms of the HDR-VDP-2 score (i.e., mean opinion score index) while reaching competitive performance in terms of PSNR and SSIM.
Snapshot High Dynamic Range Imaging with a Polarization Camera
Aug 16, 2023High dynamic range (HDR) images are important for a range of tasks, from navigation to consumer photography. Accordingly, a host of specialized HDR sensors have been developed, the most successful of which are based on capturing variable per-pixel exposures. In essence, these methods capture an entire exposure bracket sequence at once in a single shot. This paper presents a straightforward but highly effective approach for turning an off-the-shelf polarization camera into a high-performance HDR camera. By placing a linear polarizer in front of the polarization camera, we are able to simultaneously capture four images with varied exposures, which are determined by the orientation of the polarizer. We develop an outlier-robust and self-calibrating algorithm to reconstruct an HDR image (at a single polarity) from these measurements. Finally, we demonstrate the efficacy of our approach with extensive real-world experiments.
Fourier-Domain Inversion for the Modulo Radon Transform
Jul 24, 2023Inspired by the multiple-exposure fusion approach in computational photography, recently, several practitioners have explored the idea of high dynamic range (HDR) X-ray imaging and tomography. While establishing promising results, these approaches inherit the limitations of multiple-exposure fusion strategy. To overcome these disadvantages, the modulo Radon transform (MRT) has been proposed. The MRT is based on a co-design of hardware and algorithms. In the hardware step, Radon transform projections are folded using modulo non-linearities. Thereon, recovery is performed by algorithmically inverting the folding, thus enabling a single-shot, HDR approach to tomography. The first steps in this topic established rigorous mathematical treatment to the problem of reconstruction from folded projections. This paper takes a step forward by proposing a new, Fourier domain recovery algorithm that is backed by mathematical guarantees. The advantages include recovery at lower sampling rates while being agnostic to modulo threshold, lower computational complexity and empirical robustness to system noise. Beyond numerical simulations, we use prototype modulo ADC based hardware experiments to validate our claims. In particular, we report image recovery based on hardware measurements up to 10 times larger than the sensor's dynamic range while benefiting with lower quantization noise ($\sim$12 dB).
Single Image LDR to HDR Conversion using Conditional Diffusion
Jul 06, 2023Digital imaging aims to replicate realistic scenes, but Low Dynamic Range (LDR) cameras cannot represent the wide dynamic range of real scenes, resulting in under-/overexposed images. This paper presents a deep learning-based approach for recovering intricate details from shadows and highlights while reconstructing High Dynamic Range (HDR) images. We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning. Moreover, we introduce a new loss function for LDR-HDR translation tasks, termed Exposure Loss. This loss helps direct gradients in the opposite direction of the saturation, further improving the results' quality. By conducting comprehensive quantitative and qualitative experiments, we have effectively demonstrated the proficiency of our proposed method. The results indicate that a simple conditional diffusion-based method can replace the complex camera pipeline-based architectures.
Spatiotemporally Consistent HDR Indoor Lighting Estimation
May 07, 2023
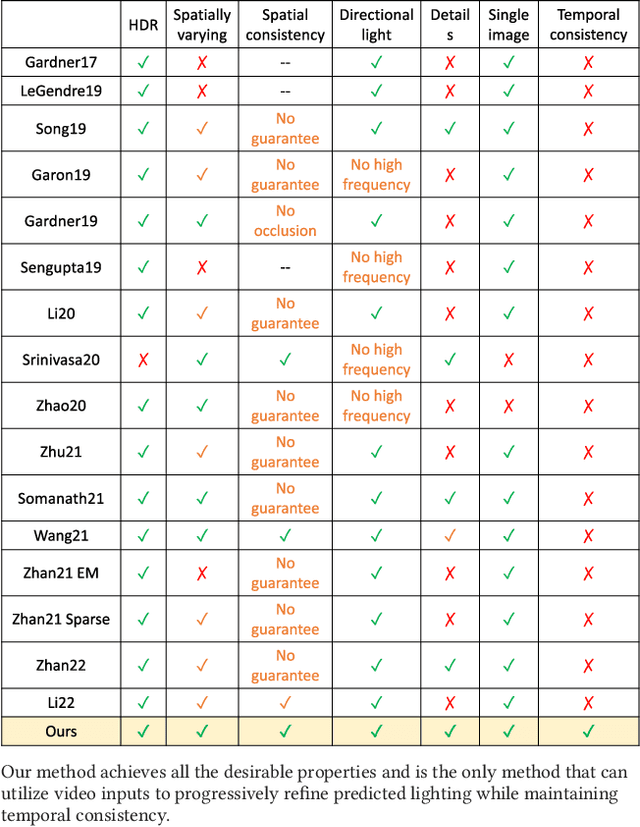
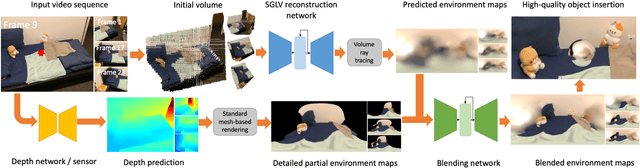
We propose a physically-motivated deep learning framework to solve a general version of the challenging indoor lighting estimation problem. Given a single LDR image with a depth map, our method predicts spatially consistent lighting at any given image position. Particularly, when the input is an LDR video sequence, our framework not only progressively refines the lighting prediction as it sees more regions, but also preserves temporal consistency by keeping the refinement smooth. Our framework reconstructs a spherical Gaussian lighting volume (SGLV) through a tailored 3D encoder-decoder, which enables spatially consistent lighting prediction through volume ray tracing, a hybrid blending network for detailed environment maps, an in-network Monte-Carlo rendering layer to enhance photorealism for virtual object insertion, and recurrent neural networks (RNN) to achieve temporally consistent lighting prediction with a video sequence as the input. For training, we significantly enhance the OpenRooms public dataset of photorealistic synthetic indoor scenes with around 360K HDR environment maps of much higher resolution and 38K video sequences, rendered with GPU-based path tracing. Experiments show that our framework achieves lighting prediction with higher quality compared to state-of-the-art single-image or video-based methods, leading to photorealistic AR applications such as object insertion.
Spatially Varying Exposure with 2-by-2 Multiplexing: Optimality and Universality
Jun 30, 2023The advancement of new digital image sensors has enabled the design of exposure multiplexing schemes where a single image capture can have multiple exposures and conversion gains in an interlaced format, similar to that of a Bayer color filter array. In this paper, we ask the question of how to design such multiplexing schemes for adaptive high-dynamic range (HDR) imaging where the multiplexing scheme can be updated according to the scenes. We present two new findings. (i) We address the problem of design optimality. We show that given a multiplex pattern, the conventional optimality criteria based on the input/output-referred signal-to-noise ratio (SNR) of the independently measured pixels can lead to flawed decisions because it cannot encapsulate the location of the saturated pixels. We overcome the issue by proposing a new concept known as the spatially varying exposure risk (SVE-Risk) which is a pseudo-idealistic quantification of the amount of recoverable pixels. We present an efficient enumeration algorithm to select the optimal multiplex patterns. (ii) We report a design universality observation that the design of the multiplex pattern can be decoupled from the image reconstruction algorithm. This is a significant departure from the recent literature that the multiplex pattern should be jointly optimized with the reconstruction algorithm. Our finding suggests that in the context of exposure multiplexing, an end-to-end training may not be necessary.
Local-to-Global Panorama Inpainting for Locale-Aware Indoor Lighting Prediction
Mar 18, 2023



Predicting panoramic indoor lighting from a single perspective image is a fundamental but highly ill-posed problem in computer vision and graphics. To achieve locale-aware and robust prediction, this problem can be decomposed into three sub-tasks: depth-based image warping, panorama inpainting and high-dynamic-range (HDR) reconstruction, among which the success of panorama inpainting plays a key role. Recent methods mostly rely on convolutional neural networks (CNNs) to fill the missing contents in the warped panorama. However, they usually achieve suboptimal performance since the missing contents occupy a very large portion in the panoramic space while CNNs are plagued by limited receptive fields. The spatially-varying distortion in the spherical signals further increases the difficulty for conventional CNNs. To address these issues, we propose a local-to-global strategy for large-scale panorama inpainting. In our method, a depth-guided local inpainting is first applied on the warped panorama to fill small but dense holes. Then, a transformer-based network, dubbed PanoTransformer, is designed to hallucinate reasonable global structures in the large holes. To avoid distortion, we further employ cubemap projection in our design of PanoTransformer. The high-quality panorama recovered at any locale helps us to capture spatially-varying indoor illumination with physically-plausible global structures and fine details.